Impostor is a web proxy, so it listens to all the traffic between your browser
and the web. It is meant to continually run (as a "service" or "daemon")
on a trusted server. We call this server the Impostor Proxy. (This could
be your office computer or some other machine that is continuously connected to
the Internet.) Users that want to use the Impostor Proxy need to adjust the
settings of their browsers accordingly.
Impostor keeps a copy of the user's long term authentication credentials
(i.e. usernames and password) in a so-called credential database. Before
the Impostor proxy can automatically log some user into a website (using the
user's appropriate authentication credentials), it needs to know which user it
is talking to. For this purpose it needs to authenticate the user. Now, if it
were to authenticate users based on a simple password, it would recreate the
problem it was meant to solve in the first place: that passwords need to be
typed into untrusted devices. Instead, Impostor uses a challenge/response
mechanism to authenticate users.
So, what is a challenge/response mechanism? It's an authentication technique
that potentially prevents long-term secrets (such as passwords) from being
exposed. Generally, it works as follows. Every time Server A
(for example, the Impostor Proxy) needs to authenticate User B (for example,
you), it issues a challenge that User B has to answer (or "respond"
to). A simple example of such a challenge is a question the answer to which only
User B knows (a suitable question could be, for example, "What are the
first, fourth and seventh characters of your passphrase?"). The trick is
that, every time this process is repeated, Server A asks a different question.
In this way, even if some untrusted Machine C (for example, some computer at an
Internet cafe), gets to know the response to one challenge, it cannot use it to impersonate
User B because next time Server A will issue a different challenge
(the correct response to which will also be different and only known to User B).
Impostor cannot, of course, automatically log users into all websites
(including those that do not exist yet). Those websites for which Impostor can
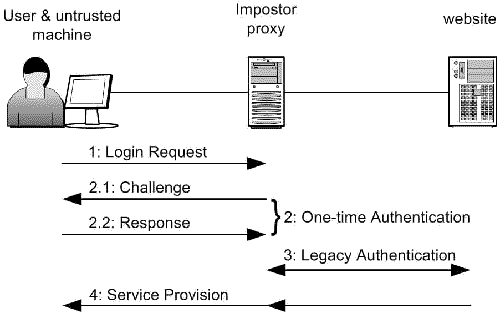
log users in, are called "SSO-enabled" websites. What happens
whenever a users tries to log into an SSO-enables website, is depicted in the
Figure below. First, Impostor recognizes the fact that the user is trying to log
into an SSO-enabled website (step 1). Then, Impostor issues a challenge (step
2.1) in the form of a web page. That web page contains the challenge (as text),
and two fields the user is prompted to fill in: the username and the response to
the challenge. This information is sent back to Impostor (step 2.2). Impostor
then verifies that the response matches the challenge. If it does not, it
responds with an error page and the process is terminated. If, however, it does,
Impostor fetches the appropriate credentials from the credential database and
executes the legacy authentication mechanism with the SSO-enabled website (step
3). This typically involves sending the user's corresponding username and
password, but other mechanisms (HTTP authentication, public key certificates,
etc) are also supported. Finally, the resulting web page is forwarded from the
website to the user's browser.
FIGURE
The content filtering functionality of Impostor is not depicted
in the figure. However, Impostor performs content filtering irrespective of
which website the user is currently visiting. For a more comprehensive
description of the design and internal workings of Impostor, you are invited to
read our IEEE GLOBECOM 2004
paper.